




 03-5946-8400
03-5946-8400
 HOME
HOME
AWS(アマゾンウェブサービス)を利用してシステムを構築・運用されている方も多いと思います。弊社でも最近よくご相談をいただきます。 今回は、AWS上で稼働するサービスにおいて発生した障害について、弊社がどのような調査、改善案の提案を行なったかという事例をご紹介します。
目次
障害発生の背景
お客様
産業廃棄処理の電子マニフェスト(JWNET)制度をより簡単に活用するためのサービスをAWSを利用してご提供されている、業界シェアno1 のお客様。
産業廃棄処理に必要な電子マニフェストを 24時間365日、いつでも簡単に発行できる便利で画期的なサービスをご提供されています。排出事業者や運搬業者、処理業者、最終処分業者といった、多数の関係者が連携・利用するので、サービスの安定稼働が重要となってきます。
弊社の関わり方
AWS 上に構築されたシステムの監視・運用全般をサポートしております。弊社の提供しているサービスについては、最後に紹介いたします。
お客様システムの環境
構成はおおよそつぎの通りです。
- ELB(Elastic Load Balancer)
- Webサーバー(IIS) 数台
- 時間帯により、稼働台数が変動します
- RDS(Relationad Database Service)
- Oracle と MSSQL
24時間365日体制でサービス提供をされていますが、ユーザの利用傾向より、平日午前中にアクセスが集中するという傾向があります。なので、アクセス数の少ない週末などはWebサーバーの稼働台数を減らすなど、よりコストパフォーマンスの高い運用を行っていらっしゃいます。
お客様システム構成図(抜粋)
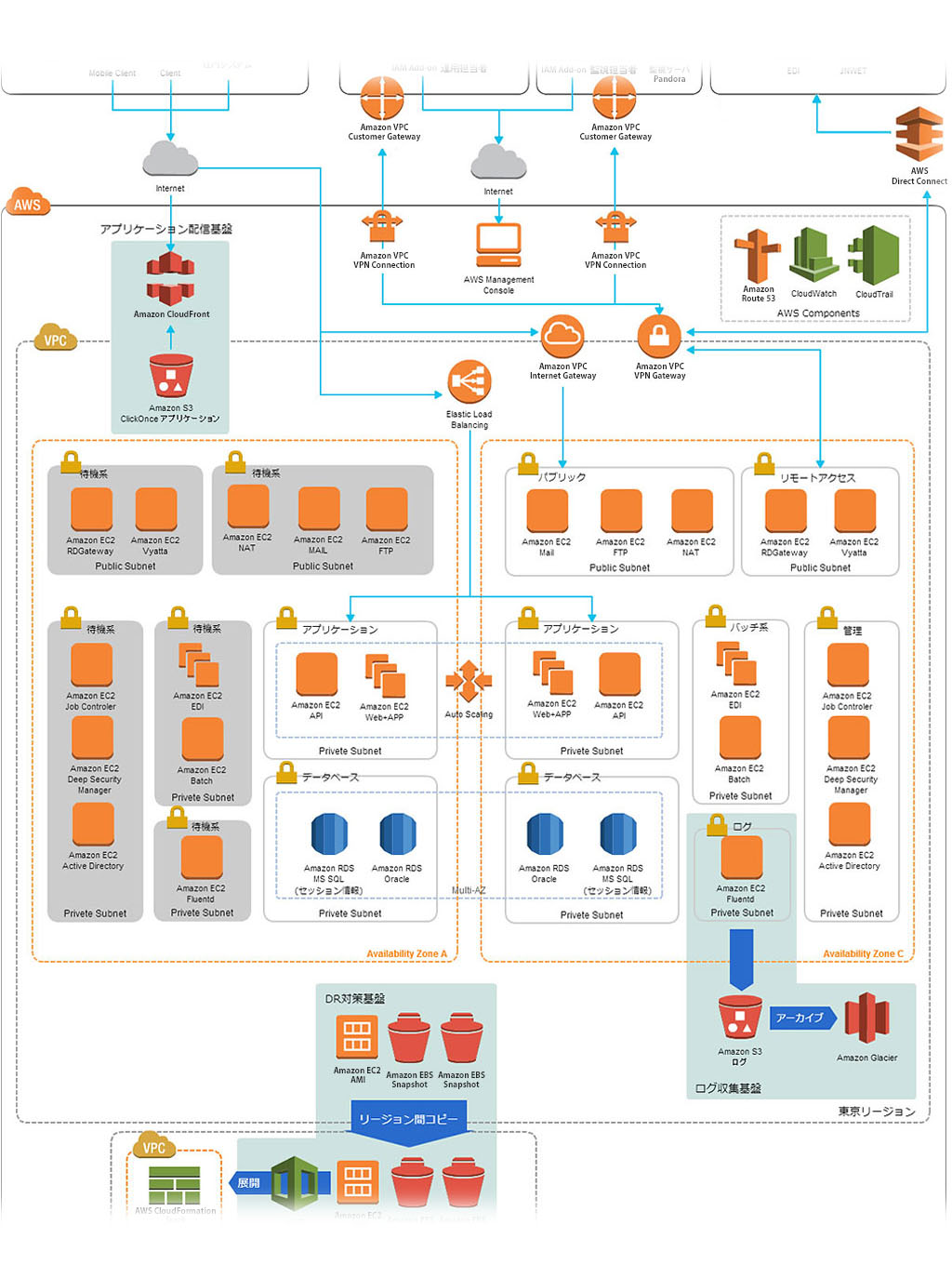
発生していた事象
ある時から、月に数回ほどIISが高負荷になり、サービスの応答時間が非常に長くなるという事象が発生。
IIS プールリサイクルの手動操作や、インスタンスの再起動やスケールアップなど一次対応を行いつつ、障害原因の根本解決を行うという道のりが始まりました。
スケールアップを実施してもIISの高負荷は解消せず
事象解決に向けた取り組み
弊社ではお客様システムの特性に合わせて、さまざまな情報収集、監視項目を設定しています。このケースでは、URL応答時間の遅延とCPU使用率とIISセッション数の急上昇に着目、関連する RDS や ELB のリソースに不足が発生していないか等を精査することからスタートしました。
合わせて、直近のサービス利用ユーザ数やアクセス傾向に変化が見られないか、お客様に調査いただくなど、協力して問題解決に取り組みました。
弊社では、インスタンス内部にて情報収集を行う、エージェント型監視とインスタンスの外部から情報収集を行う、エージェントレス監視を適当に組み合わせて監視しております。
今回の事象では、CPU 使用率が高くなることから、エージェントによる監視情報収集が欠落することがありましたが、CloudWatch により取得できる情報(エージェントレス監視)を組み合わせることで、インスタンスの状況を速やかに把握することができました。
また、障害発生時の状況確認などを手順化することで、速やかな状況確認、対応が行えるよう努めています。
一次対応で障害を最小限に
まずは被害を最小限に食い止めるため、負荷が高い状態が継続しているサーバーをサービスから切り離し、再起動してサービスへ戻す、という一次対応を行いました。また、負荷上昇に対応するため、インスタンスのスケールアップを実施しました。
スケールアップなどの二次対応を実施するも、再度発生
が、しばらくすると同じ事象が発生したため、リソース情報やログ出力を元に
- MSSQL のインスタンスタイプを変えたり、
- IISのアプリケーションプールリサイクルの設定を変更したり、
- 週末の稼働台数を増やしたり、障害時に予備サーバーを起動したり、
を試みましたが、また同じ事象が発生することから、根本原因を特定しないと問題解決は難しい、という結論にいたりました。 (このとき、リソース分析情報を元に、インスタンスタイプを元に戻すなど調整を行い、速やかにコスト削減できるよう努めました。)
根本原因を特定するため、ELBやIISのアクセスログを解析
お客様との協力により、特定のユーザからのアクセスが、高負荷の原因であることが判明
ELBやIISのアクセスログを確認し、処理に時間がかかっている箇所を特定しました。また、特定の携帯機種からのアクセス時に、特に処理に時間がかかっていることがわかり、アクセス内容と処理時間に着目したグラフを作成、お客様へ提出しました。
この情報を元に、お客様にて携帯機種とアクセスIDを突き合わせ、原因と思われるエンドユーザを特定でき、アプリケーションの観点から、障害原因を究明いただきました。
また、この問題を回避するために、インフラ視点からどのような対応が可能か、検討、提案を行いました。
解決に至るまでの回り道
上記結論に至るまで、先に書いた通り、結果的にいろいろと回り道をしました。
- 障害発生のタイミングが Windowsアップデートのタイミングと近接していたことから、Windowsアップデートであてたパッチにより、アプリケーションの動作に影響を与えているのでは?と考えたこともありました
- サーバー再起動の直後は障害が発生しない、というタイミングもあったため、定期的なサーバー再起動を実施するか否かについても、お客様と議論しました
- 障害が発生したタイミングのイベントログを確認したところ、IIS のプールリサイクルが、メモリ使用量閾値超過により実行されていることを確認。かつ、このリサイクル処理がタイムアウトとなっており、セッションが強制的に切断されていることが確認できました
この情報を元に、プールリサイクルの条件見直しや、インスタンスタイプ変更によるメモリ割当量の変更も実施しました - 障害が発生したタイミングを含め、MSSQL の CPU 使用率が高いタイミングがあったため、インスタンスサイズの見直しを実施しました
上記のように、可能性がある箇所を一つずつ調査、対応を行うことで、原因と思われる箇所を減らしていくことを繰り返しました。
また、サービスのダウンタイムを最小限に留めるよう、インスタンスの追加を行う基準や手順の作成を実施しました。と同時に、障害が発生していることを、お客様の運用チームだけではなく、営業やサポートチームへも通知する基準や仕組みの作成も行いました。
弊社では、継続的なモニタリング情報を元にする、障害となりうる要因の洗い出しや、お客様と協力した改善策の検討などを行なっております。リソース情報などを元にしているため、サーバーなどインフラレイヤーからボトムアップで原因を調査することを得意としています。
起こっている障害を、なる早で解決するための3つのポイント
- 常日頃から、データを収集して貯め、分析しましょう
- 障害を最小限に食い止めるための、手順書作成も重要です
- インフラレイヤからアプリケーションレイヤまでの情報を統合して判断すること
常日頃から、データを収集して貯め、分析しましょう
意外と難しいのが、いつ、どのような条件で、スケールアップ / スケールアウトするか?インスタンスを減らすのか?の判断です。常日頃から様々な情報を収集・蓄積・分析することで、これらのタイミングも判断しやすくなります。また、平時と障害発生時のデータ比較ができるので、根本原因の解決もしやすくなります。
例えば、CloudWatch で収集するクラウドコンピューティングのリソース情報だけでなく、インスタンス上で稼働する各種情報を統合管理できると、迅速な対応ができるようになります。
障害を最小限に食い止めるための、手順書作成も重要です
基本的に、障害はいつ起こるかわからないもの。起きてしまった場合の被害を最小限に抑えるための方針の策定やエスカレーションフローの整理、また誰でも対応できるような手順書作りも重要になってきます。
(何より大事なのが)インフラレイヤからアプリケーションレイヤまでの情報を統合して判断すること
「サービスが正常に稼働している状態とは何か」を、要素(アプリケーションの挙動、サービス応答、関連プロセスの稼働、関連インスタンスの稼働、リソース利用状況)に分解して考えていくこと、障害箇所を思い込みで特定せず様々な視点で考えていくこと、が重要です。
おわりに
最後に弊社サービスについて、簡単にご紹介させてください。
- 弊社は、クラウド環境/オンプレ環境問わず、システムの運用管理サービスをご提供しています
- システム監視や障害対応だけでなく、月次レポーティング、サーバーの設定変更や、ユーザ管理、システム構成管理、Active Directoryの運用管理など、日々発生する運用の代行も行っております
- 監視運用に必要な権限をお客様からいただくことで、あらゆる情報を収集・管理させていただいているため、障害原因の解決や、運用改善、運用代行といったことも行いやすいのかな、と思っています
- 今回のケースは、日々収集したデータをもとに、毎月の定例ミーティングでお客様とブレストし、協力しながら、進めさせていただきました
- 「何が起こっているかわからないんだけど、障害はとにかく早く解消したいから相談にのって」というお話は得意分野です
お気軽にご相談ください。
アールワークスのサービス

AWS運用代行サービス
AWSの導入から運用までを一括サポートする、AWS運用代行サービス。お客様システムに即した監視項目、運用フローの設計や、24時間365日の監視・障害対応を代行。障害の根本解決や、システムのボトルネックの解消など、恒久対策も代行します。



Contactお問い合わせ
お見積もり・ご相談など、お気軽にお問い合わせください。