




 03-5946-8400
03-5946-8400
 HOME
HOME
こんにちは、打田です。
みなさん AWS は利用されているかと思いますが、 今回は AWS でシステムを動かす際にインスタンス単体からでは取得できない AWS EC2 インスタンスのステータスチェック監視について紹介します。
EC2 インスタンスステータスチェックとは
そもそも AWS EC2 インスタンスステータスチェックとは AWS が実施しているインスタンス正常性テストのことです。 ステータスチェックの結果は、AWS Management Console の EC2 ダッシュボード上では 以下のように表示されているかと思います。
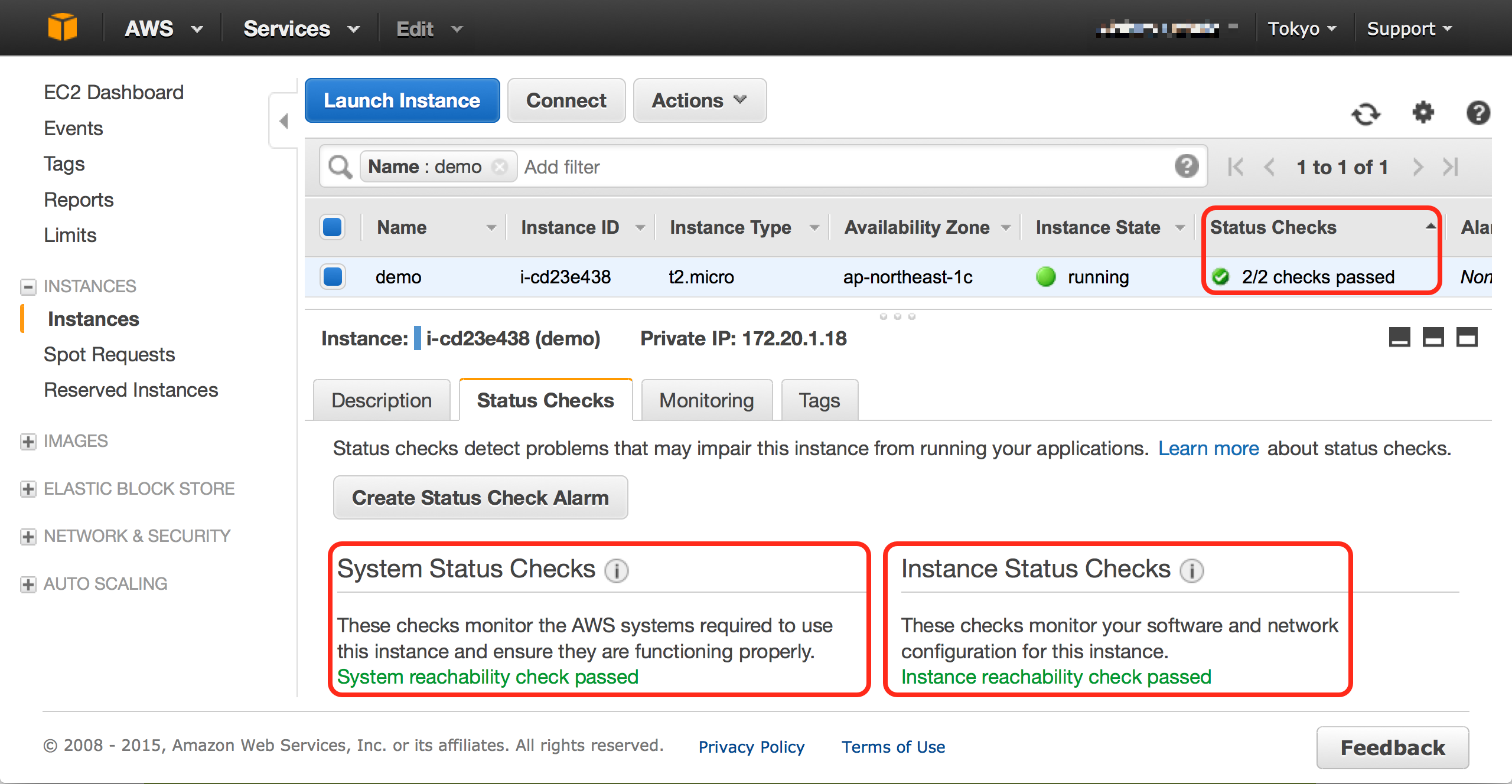
このステータスチェックには
- System Status Checks
- Instance Status Checks
の2種類があることが確認できます。
「System Status Checks」はネットワークパケットが到達しているかを確認しており、 失敗した場合は AWS のインフラ(電源、ネットワーク、物理ホスト等)で問題の発生している可能性があります。 「Instance Status Checks」は OS がパケットを受信できているか確認しており、 OS や ファイルシステム、ネットワーク設定等で問題の発生が発生している可能性があります。
ステータスチェックは System は AWS 内部に問題が、Instance の場合はインスタンス側に問題があると 考えればよいかと思います。
上記に示した AWS Management Console EC2 ダッシュボード上では System/Instance 両者のステータスチェックが passed で 正常となっているため、「2/2 checks passed」でインスタンスの状態が正常であることが確認できます。
EC2 インスタンス上でのサービスやプロセスの動作状況はソフトウェアエージェント等で情報収集・監視することができますが、 AWS 内部で障害が発生している場合に状況判断することは難しいかと思います。 しかし、このステータスチェックを取得することで、AWS 内部で障害が発生している場合に素早く反応し、 対応することができるようになります。
AWS EC2 経由での情報取得
このステータスチェックは EC2 の API 経由で情報取得することができます。 awscli を利用する場合は アクセスキーを適切に設定した上で以下のようなコマンドで取得することができます。
$ aws ec2 describe-instance-status --instance-ids インスタンスID
{
"InstanceStatuses": [
{
"InstanceId": "インスタンスID",
"InstanceState": {
"Code": 16,
"Name": "running"
},
"AvailabilityZone": "ap-northeast-1b",
"SystemStatus": {
"Status": "ok",
"Details": [
{
"Status": "passed",
"Name": "reachability"
}
]
},
"InstanceStatus": {
"Status": "ok",
"Details": [
{
"Status": "passed",
"Name": "reachability"
}
]
}
}
]
}
この結果をjqを利用し加工することで、 簡単にシェルスクリプトでも監視スクリプトを書くことができます。
例えば、System Status を取得したい場合は以下のようにして取得できます。
$ aws ec2 describe-instance-status --instance-ids インスタンスID | jq -r .InstanceStatuses[].SystemStatus.Status ok
もちろん、シェルスクリプト以外にお好みの言語で書いても構いません。 単純な例をいくつかの言語で示すと以下のようになります。
Python で boto を利用するなら
import boto.ec2
c = boto.ec2.connect_to_region('ap-northeast-1')
status = c.get_all_instance_status(instance_ids=['インスタンスID'])
for s in status:
print s.system_status
Ruby で AWS SDK for Ruby を利用するなら
require 'aws-sdk'
ec2 = Aws::EC2::Client.new(region: 'ap-northeast-1')
res = ec2.describe_instance_status(instance_ids: ['インスタンスID'])
res.instance_statuses.each {|s|
puts s.system_status.status
}
Go で AWS SDK for Go を利用するなら
package main
import (
"fmt"
"github.com/awslabs/aws-sdk-go/aws"
"github.com/awslabs/aws-sdk-go/service/ec2"
)
func main() {
client := ec2.New(&aws.Config{Region: "ap-northeast-1"})
instance_ids := []*string{aws.String("インスタンスID")}
input := ec2.DescribeInstanceStatusInput{InstanceIDs: instance_ids}
res, err := client.DescribeInstanceStatus(&input)
if err != nil {
panic(err)
}
for _, status := range res.InstanceStatuses {
fmt.Println(*status.SystemStatus.Status)
}
実際に監視を導入する際の注意としては、 ステータスチェックで異常が発生する場合は AWS の内部や OS レベルでの重大な問題が発生しているため、 インスタンス上で動作するソフトウェアエージェントが正常に情報を送信できない状況となることです。 そのため、ステータスチェック監視はソフトウェアエージェントではなく、監視サーバーから定期的に ステータスチェックの値を確認することになります。
PandoraFMS による監視サーバーからの定期的なチェックの仕組みについて知りたい方は リモートモニタリング – Pandora FMS Wiki をご参照下さい。
自動検出による監視登録自動化
AWS を利用している場合、AutoScaling 等でインスタンス増減が実施することも多いかと思います。 インスタンス数が変わる度に上記の Status Check の情報収集・アラートの設定を 追加していくのは現実的ではありません。
PandoraFMS には 自動検出機能 が あるため、自動検出スクリプトを書くことで、上記のインスタンス一覧を取得し一括で監視追加することができます。
自動検出機能の動作を概要を図示すると以下のようになります。
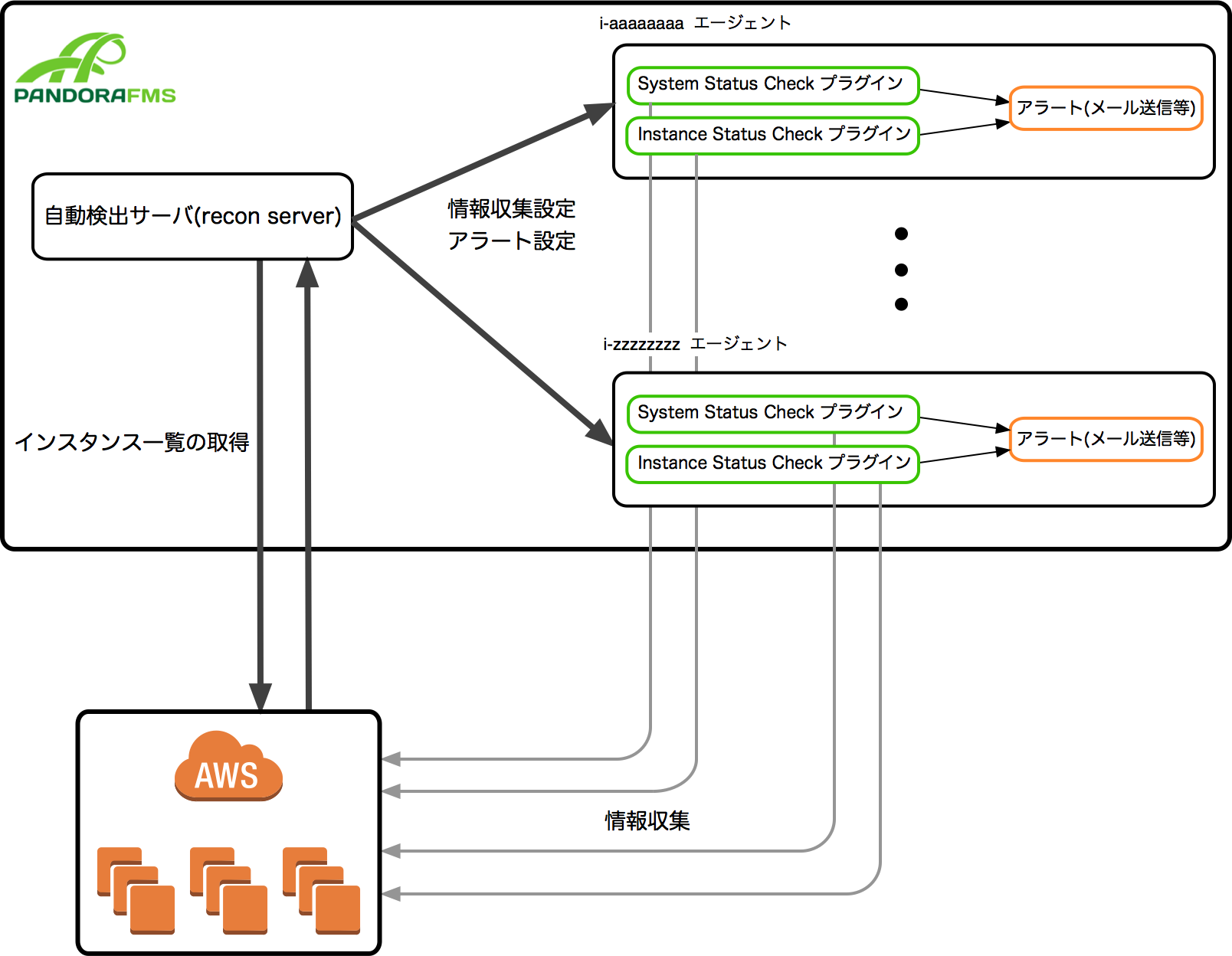
この機能を利用すると、自動検出タスクを実行することでインスタンス一覧を取得し、 取得したインスタンス全てに対して情報収集の設定やアラートの設定を一括で行なうことができます。
この機能を以下のようなタイミングで利用することで
- 定期的に自動検出タスクを実行
- インスタンスに変更を加えた後に自動検出タスクを実行
インスタンスの数の増減する場合でも手間をかけず、監視登録やアラート設定を自動化できます。
CloudWatch との比較
ここまででは、EC2 ステータスチェックを AWS の EC2 API 経由で取得する方法を紹介しました。 一方、ステータスチェックは以下の CloudWatch メトリックとしても取得することができます
- StatusCheckFailed
- StatusCheckFailed_Instance
- StatusCheckFailed_System
末尾に Instance/System を含むものははその名の通り、それぞれ Instance と System ステータスチェックの状態を示し、 チェックに失敗した場合に 1 を、チェックに成功した場合に 0 を返します。 StatusCheckFailed は Instance Status Checks と System Status Chekcs のいずれかが失敗した場合に 1 となり、 それ以外、つまり両者が正常な場合に 0 を返します。
CloudWatch で取得する情報は一定期間内の統計量を取得するという仕組みになっているため、 取得している値が
- 直近何分間で集約されているのか
- どの統計量(平均/最大値/最小値など)なのか
といった点に注意する必要があります。
今回紹介したステータスチェックの方法は、EC2 の API を介して情報収集を行います。 そのため1分毎に更新される AWS Management Console の EC2 ダッシュボード上の表示と 同等のものとなります。 そのため、最新の状況を単純に確認するのに適しています。
一方で、CloudWatch を利用した場合は取得するデータの集約期間を変更したり、 平均以外のデータサンプル数や合計といった統計量も取得できるため、 障害発生後に発生履歴などを確認する場合に便利です。
PandoraFMS による障害直後の確認
さらに、PandoraFMS の以下の機能を利用することで、障害発生直後の状況を PandoraFMS 上に集約することができます。
モジュール強制実行機能を利用すると、監視コンソール上のボタンを押すことで強制的にプラグインを再実行することができます。 これにより、現状も障害継続しているか素早く状況確認できます。
集中監視機能を利用すると障害発生した際にプラグインの実行間隔を変更することができるため、 障害発生時の確認を監視サーバーが自動的に高頻度で実施するといったことが可能です。
ステータスチェック失敗時のトラブルシューティング
システムステータスで失敗した場合はインスタンスが載っているホスト上の問題と考えられるため、 基本的にインスタンスを Stop した後 Start することで、動作ホストを変更します(EBS Backed Instance の場合)。
また、ステータスチェックに失敗し20分以上該当のインスタンスにアクセスできない場合は AWS ベーシックサポートの対象ですので、AWS サポート支援を受けることができます。
AWS が以下のトラブルシューティングのドキュメントを提供しているため、こちらも一読することをおすすめいたします。
最後に
本稿では EC2 インスタンスのステータスチェック監視について紹介しました。 EC2 インスタンスと同様に RDS のステータスや ELB ヘルスチェックステータスでも 同様のステータスチェックを実施し監視することもできます。
参考資料
監視ツール

大規模システム向け統合システム監視ツール Pandora FMS Enterprise
世界194か国から120万ダウンロード以上の支持を得るオープンソースの監視ツール Pandora FMSに、大規模システム向け機能を追加した Pandora FMS Enterprise。オープンソースベースの商用製品だから実現できる「運用コストの削減」と「使い勝手の良さ」が特徴です。


資料ダウンロード
課題解決に役立つ詳しいサービス資料はこちら

-
-
統合システム監視ツール Pandora FMS Enterprise カタログ
直感的で操作性に優れたユーザインターフェイスを持ち、1つのシステムでマルチテナント環境を実現できる統合システム監視ツール Pandora FMS Enterprise、Pandora FMS Enterprise SaaS の機能、サポート内容、料金をご確認いただけます。
-
Tag: Pandora FMS



Contactお問い合わせ
お見積もり・ご相談など、お気軽にお問い合わせください。