




 03-5946-8400
03-5946-8400
 HOME
HOME
目次
Kubernetesヘルスチェックの概要、種類、設定例、ベストプラクティス、クラウドプロバイダーとの統合について
Kubernetes ヘルスチェックは、クラウドネイティブなアプリケーションの運用環境において重要な役割を果たしています。
本記事ではヘルスチェックの概要、ヘルスチェックの種類、それらの使い分け、設定方法、実装上のベストプラクティスなどを紹介します。
1. Kubernetesヘルスチェックとは
Kubernetes におけるヘルスチェックは、クラスタ内のアプリケーションやサービスが正常に動作しているかどうかを定期的に確認し、必要に応じて適切な対応を行う仕組みです。
ヘルスチェックが求められる理由として重要なポイントは以下の通りです。
高可用性の確保
ヘルスチェックにより、アプリケーションが正常に動作しているかどうかを確認し、異常が検出された場合には自動的な対応を行うことができます。これにより、アプリケーションの高可用性が確保され、サービスの中断やユーザーエクスペリエンスの低下を最小限に抑えることができます。
トラフィックの適切な配分
ロードバランサー機能と連携し、ヘルスチェックで異常を検出した場合、不備のあるアプリケーションに対し、トラフィックの転送を回避することで、ユーザーエクスペリエンスを維持することができます。
スケーラビリティと効率の向上
ヘルスチェックを活用することで、スケーリングやアプリケーションの増減に柔軟に対応できるようになります。アプリケーションが正常であれば自動的にトラフィックを受け入れ、逆に異常を検出した場合には自動的に減少させることができます。
ライフサイクル管理への貢献
ヘルスチェックは、アプリケーションのライフサイクルにも大きな影響を及ぼします。ライフサイクル管理にKubernetesのヘルスチェックを組み合わせることで、システム全体の信頼性と可用性を高めることができます。
特に大規模で複雑なクラウドネイティブアプリケーションのデプロイメントにおいては、ヘルスチェックの適切な実装が致命的な障害を回避し、ビジネスの継続性向上に役立ちます。
2. Kubernetesヘルスチェックの種類について
Kubernetes ヘルスチェックには2つの種類が存在します。それぞれについて解説します。
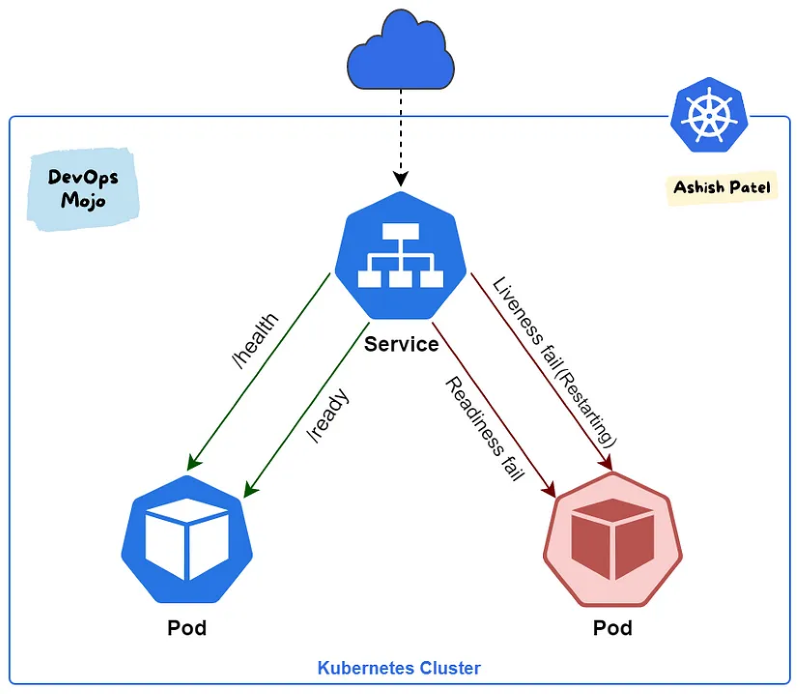
Liveness Probe(生存確認)
Liveness Probe は、アプリケーションが正常に動作しているかどうかを確認します。アプリケーションのクラッシュやフリーズなどの致命的な状態を検出し、アプリケーションを健康な状態に保つことができます。もしアプリケーションが停止している場合、 Kubernetes は自動的に Pod を再起動します。
Readiness Probe(準備確認)
Readiness Probe は、アプリケーションがリクエストを処理する準備ができているかどうかを確認します。これにより、アプリケーションが適切に起動し、サービスに参加するまでの時間を待機させることができます。
もしリクエストを処理できる状態でない場合、ロードバランサーやサービスディスカバリメカニズムを制御し、アプリケーションへのトラフィックを送らないようにすることができます。
ヘルスチェック設定例
Kubernetes ヘルスチェックの設定は、 Pod のコンテナ定義内で行います。具体的には、Liveness Probe と Readiness Probe を指定し、 HTTP リクエスト、 TCP ソケット、コマンド実行などの形式でアプリケーションのヘルスチェック実行を定義します。
Liveness Probeの設定例
HTTP リクエストを使用する場合
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 3
periodSeconds: 3
この例では、/healthz エンドポイントに対して HTTP GET リクエストを送り、初期遅延後に3秒ごとに再試行します。
TCPソケットを使用する場合
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 3
periodSeconds: 3
この例では、ポート8080に対して TCP ソケットの接続を試行し、初期遅延後に3秒ごとに再試行します。
Readiness Probeの設定例
HTTP リクエストを使用する場合
readinessProbe:
httpGet:
path: /readiness
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
この例では、/readiness エンドポイントに対して HTTP GET リクエストを送り、初期遅延後に5秒ごとに再試行します。
TCPソケットを 使用する場合
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
この例では、ポート8080に対して TCP ソケットの接続を試行し、初期遅延後に5秒ごとに再試行します。
図版出典:Medium
3. Kubernetesヘルスチェックのベストプラクティス
Kubernetes ヘルスチェックの実装における注意点を踏まえ、いくつかの重要なベストプラクティスを紹介します。
冗長性を確保する
複数のヘルスチェックを使用し、アプリケーションを異なる観点から確認することが重要です。例えば、 HTTP ヘルスチェックと TCP ヘルスチェックを併用し、それぞれの状態から障害状況を分析することでより的確な対応が可能になります。
適切な遅延と間隔を設定する
initialDelaySeconds や periodSeconds などの設定は、ヘルスチェックが開始される時間や再試行間隔の値です。再試行値は誤検知を防ぐ意味でも重要な値であり、アプリケーションの起動や応答時間に合わせて適切に設定する必要があります。
リソース使用量を最小化する
ヘルスチェックがアプリケーションに負荷をかけすぎないように注意することも重要です。高頻度なヘルスチェックにより、アプリケーションやネットワークに不必要な負荷がかかる可能性があります。
ログを適切に活用する
ヘルスチェックの結果やエラーに関する情報をログに残し、トラブルシューティングや障害発生時の分析に活用することができます。注意点としては、膨大な情報量となるため、冗長なログの記録は避け、必要な情報のみを残す設定が推奨されます。
異常検知を統合する
ヘルスチェックの結果に対して異常検知システムを統合し、自動的なアラートや対応措置をトリガーすることで、異常が早期に発見され、一元的な情報の収集とともに迅速な対応が可能となります。
4. クラウドプロバイダーとのヘルスチェック統合について
Kubernetes ヘルスチェックは、それぞれのクラウドプロバイダーの環境に応じたチェック機能を活用することができます。ここでは主に AWS 、 Azure 、GCP についてのヘルスチェック機能統合について概要を紹介します。
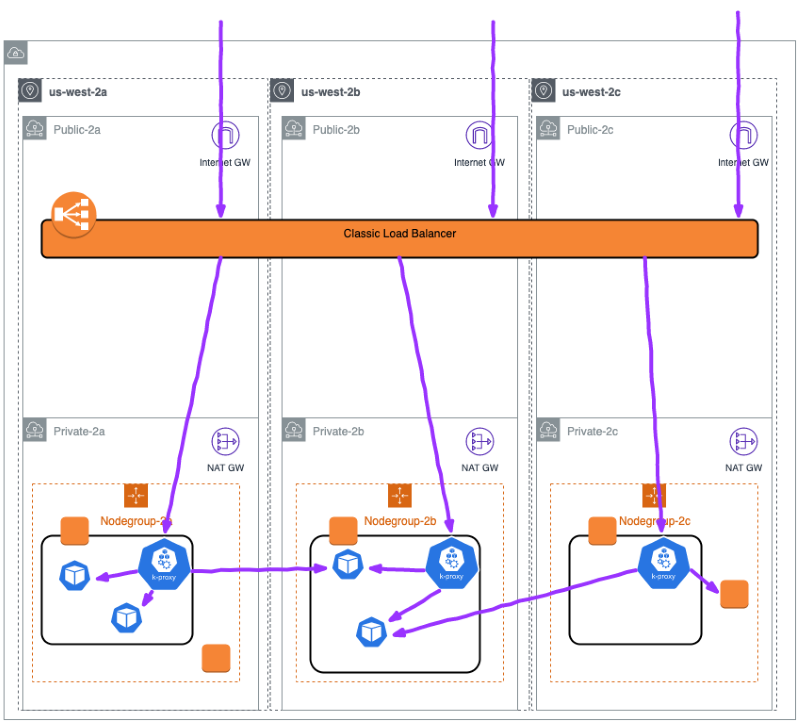
クラウドプロバイダーのLoad Balancerとの統合をする
クラウドプロバイダーの Load Balancer を使用して、 Kubernetes サービスを公開し、Load Balancer がヘルスチェックを実施することが可能です。 Pod における Service オブジェクトの type を Load Balancer に設定し、必要に応じてヘルスチェックを構成することができます。
AWS Classic Load Balancer ( CLB )、 Google Cloud Load Balancing 、 Azure Load Balancer などを利用し、構成することができます。以下は CLB を使った構成サンプルです。
図版出典:EKS Best Practices Guides – GitHub Pages
クラウドプロバイダーのモニターサービスと統合する
アプリケーションのヘルスチェック結果やメトリクスを収集し、ダッシュボードを作成できる機能や、アラートルールを設定により通知を受け取るなどが可能です。Kubernetes ヘルスチェックの結果をクラウドネイティブな監視・通知システムに統合し、アプリケーションの可用性を確保することができます。
詳細な手順や設定方法は各クラウドプロバイダーの公式ドキュメントやサポートリソースを確認することを推奨いたします。
5. まとめ
ヘルスチェックを実装することで障害やエラーが早期に検出され、アプリケーションの可用性が向上し、障害への対応時間が短縮され、ビジネスの中断を最小限に抑えることができるようになります。
またアプリケーションが正常に動作しているかどうかを常にモニタリングすることで、エンドユーザーへのサービス提供の品質も向上します。 このように Kubernetes ヘルスチェックはサービスの安定性、可用性、拡張性、セキュリティを向上させることに役立ち、ビジネスにとって重要な要素と言えるでしょう。
Kubernetes の運用を相談したい





よく読まれる記事
- 1 Kubernetes のアーキテクチャとは?特徴と基本コンポーネントからデータ保護の方法まで詳しく解説2024.01.30
- 2 Kubernetes マニフェストとは?Kubernetesの構成を定義する方法について解説します!2024.02.01
- 3 Kubernetes DaemonSetとは?概要とその役割、用途、設定や運用上の注意点を解説2024.02.05
- 4 Kubernetesの重要な構成要素である「Node」について解説します!2024.03.25
- 5 Kubernetes Namespace(名前空間)とは?役割や必要性2024.02.06
Category
Contactお問い合わせ
お見積もり・ご相談など、お気軽にお問い合わせください。