




 03-5946-8400
03-5946-8400
 HOME
HOME
目次
Kubernetes を利用する際、可用性の向上に重要となる要素とは?HPA(水平Pod自動スケーリング)について分かりやすく解説
現代のビジネスにおいては、システムの負荷が急上昇してもサービスを停止することは許されません。しかし、ピーク時の負荷に合わせてリソースを維持していては大きなコスト上昇を招いてしまいます。
Kubernetes の自動スケーリングは、負荷の大きな変動が見込まれるシステムにおいても高い可用性とコスト最適化をもたらす機能として注目されています。
本記事では自動スケーリングを実現する Kubernetes 水平 Pod 自動スケーリング(以下 HPA )について、その概要や役割、仕組み、設定とトラブルシューティングなどを解説します。
1. Kubernetes HPA の概要
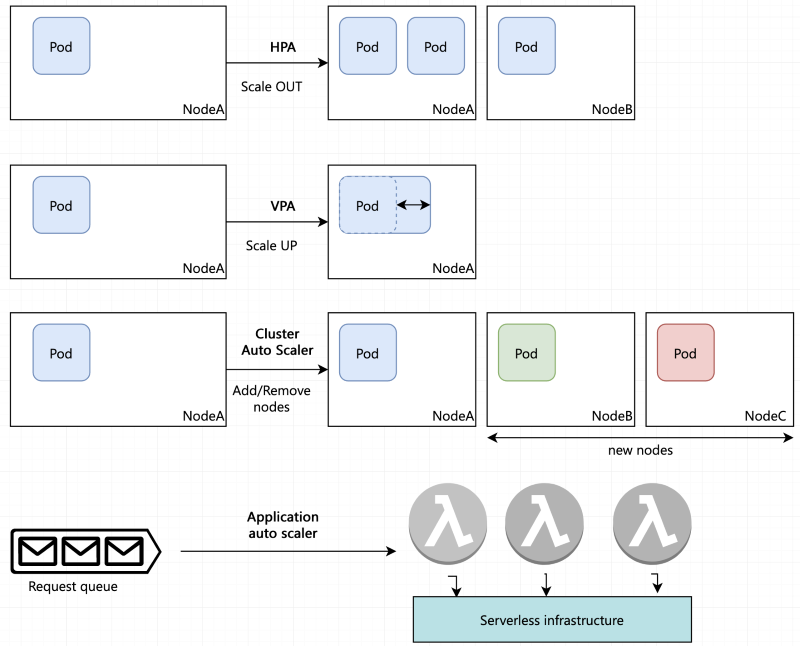
自動スケーリングとは、負荷の増減に応じてサーバ台数の増減やスペックの上げ下げを自動的に行うことです。HPA は Horizontal Pod Autoscaler の略で、負荷の増減に対応するために Pod のレプリカ数の増減を自動的に調整します。
Kubernetes の自動スケーリングには、 HPA の他にも Pod のリソース(メモリ、 CPU )を調整する「垂直 Pod 自動スケーリング」、クラスタ内の Node 数を調整する「クラスタ自動スケーリング」があります。
図版出典:DEVPRESS
自動スケーリングの目的
自動スケーリングを利用する主な目的として、可用性の向上やコスト最適化が挙げられます。
- トラフィック量やクライアントのリクエスト数などの増加に合わせてアプリケーション Pod を自動的に増やし、ダウンタイムの削減や最適なパフォーマンスの維持を行う。
- 休日やオフピーク時間帯にアプリケーション Pod の数を減らすことでコスト削減を行う。
- スケーリングが自動で行われることで、運⽤オペレーションの負荷が軽減される。
2. Kubernetes HPAの仕組み
仕組みと動作
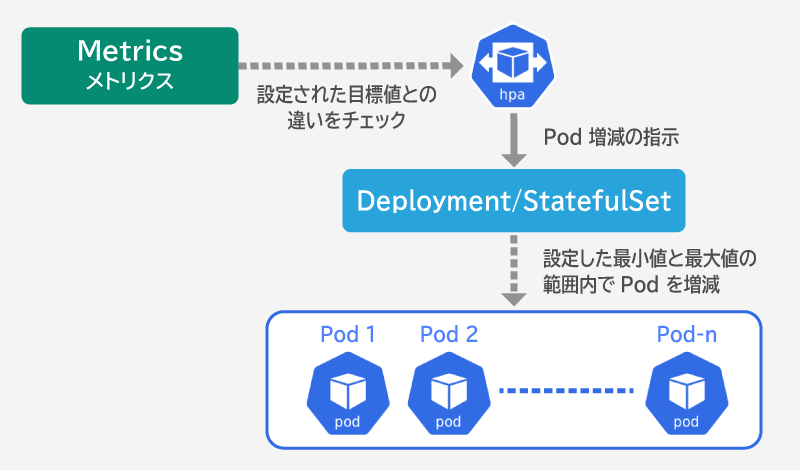
HPA は以下のような仕組みで動作します。
- Kubernetes は制御ループの中で HPA を定期的(デフォルトの間隔は 15秒)に動作させる。
- HPA は CPU 利用率などの観測可能な「メトリクス」と呼ばれる指標を取得し、設定された目標値との違いをチェックする。
- チェック結果に応じて、 HPA はワークロードリソース( Deployment や StatefulSet など)に対し、 Pod 増減の指示を出す。
- Pod の増減は、設定した最小値と最大値の範囲内で行われる。
メトリクスの種類には以下があります。
- リソース使用量: CPU またはメモリ使用量。
- カスタム指標: クライアント要求数や I/O 書き込み数などの Kubernetes オブジェクトに提供される任意の指標。ネットワークがボトルネックになりやすいアプリケーションの場合などに有効。
- 外部指標:キューに入れられたタスクの数など、クラスタ外のアプリケーションやサービスから得られる指標。
注意していただきたいのは、 HPA は Pod のレプリカ数を増減するものであって、リソースサイズを増減させるものではないことです。リソースサイズのスケールは垂直 Pod 自動スケーリングの機能です。
また、 Pod レプリカを増やし続ければ Node のリソースが足りなくなるため、 Node のスケールが必要となりますが、それはクラスタ自動スケーリングが行います。
HPA の制限
スケーリングができないオブジェクト( DaemonSet など)には HPA は適用されません。また、 HPA は Pod レプリカ数の自動調整機能ですので、Pod 増減で解決できない問題にも適用できません。
HPA オブジェクト数に制限はありませんが、オブジェクト数があまりにも多いと、メトリクスのチェック間隔がデフォルト設定の 15 秒を超えてしまう場合があります。
3. Kubernetes HPA の設定
設定の大まかな流れ
HPA を設定する際の大まかな流れは以下のとおりです。
- 平常時とピーク時にそれぞれ必要な Pod 数を把握します。
- 対応すべき負荷に連動するメトリクスを選定します。
- 必要 Pod 数や選定したメトリクスを元に設定を行います。
- 実際の動作を見ながらチューニングを行います。
リソース使用量のメトリクスを例とした設定のポイント
メトリクスとして CPU やメモリ使用量を用いる場合のポイントとなる設定項目を紹介します。
minReplicas、 maxReplicas
Pod 数の下限と上限を設定します。スケールはこの範囲内で行われます。下限は平常時のリクエストをある程度の余裕を持って捌ける Pod 数、上限はピーク時に想定される負荷を捌けるであろう Pod 数を設定しましょう。
resource requests
Pod が最低限必要とする CPU とメモリの使用量です。これは HPA が使用率の計算元として参照する値です。
target averageUtilization
使用率の目標平均値で、HPA はこの値を維持するようスケールを行います。
この値はターゲット中の全 Pod の平均値ですので、例えば 80% に設定していたとしても、中には使用率 100% を超える Pod もあり得ることに注意が必要です。
behavior フィールド
Kubernetes 1.18 ( APIバージョン autoscaling / v2beta2 )以降からは、一度にスケーリングする量の指定など、挙動を細かく設定できる behavior フィールドが使用可能となっています。
やるべきこと、やってはいけないこと
設定の際には適切なメトリクスを選定することが大切です。
- スケーリングの目的に合致するもの
- 負荷の変化に敏感で確実に反応すること
- 値を安定的に取得できること
リソース使用量のメトリクスを利用する際は、 HPA と垂直 Pod 自動スケーラーを同じメトリクスに対して併用してはいけません。HPA が使用率計算に用いる resource requests の値を垂直 Pod 自動スケーラーが変動させるため、 HPA は負荷の正確な判断が出来なくなってしまいます。
4. Kubernetes HPA の運用上の注意点
設定後は運用を通して状況を観察し、実状に合わせて設定値を調整するチューニングや、発生する問題への対応が必要です。
設定値のチューニング
スケールの結果 Pod レプリカ数が多すぎるか少なすぎる場合は、 target averageUtilization の値とともに、 resource requests の値も見直しましょう。スケールしすぎる場合は resource requests の値を大きくして Pod レプリカ数を抑えます。足りない場合はその逆です。
負荷の急激な上昇にスケールが間に合わない場合は、 behavior フィールド中の一度に増加する Pod 数や増加間隔の秒数を調整しましょう。
スケールは正常に行われているのに効果が現れないという場合、使用しているメトリクスが適切なのか、またはそもそも Pod レプリカ数の増減によって解決する問題なのかを見直してみましょう。
代表的な問題とトラブルシューティング
スラッシング
メトリクス値の変動具合によって、前回のスケーリングが完了する前に新しいスケーリングが行われ Pod レプリカ数が頻繁に上下動を繰り返す、スラッシングまたはフラッピングと呼ばれる現象があります。
この現象は stabilizationWindowSeconds フィールドを調整することで抑止できます。設定された秒数以前まで遡って望ましい Pod レプリカ数を選択するようになり、不要な変更が回避されます。
メッセージ “unable to fetch pod metrics for pod xxx: no metrics known for pod”
メトリクスサーバの起動時に表示されるのは正常動作ですが、それ以外でこのメッセージが表示され続け、実際にメトリクスを取得できない場合は問題です。
これは新しく Pod を追加した場合に起こりがちなエラーで、必要な計算を実行できていない状態です。このような場合は Pod 内のコンテナごとにリソース要求を指定しているかを確認しましょう。
5. まとめ
本記事では、 Kubernetes HPA の仕組みとその適切な設定および運用の注意点について解説しました。
HPA は負荷の増減に合わせて Pod レプリカ数を自動で調整してくれる優れた機能ですが、トラブルシューティングの項で述べたように実際に運用するといろいろな問題が起こり得ます。一度設定すればそれで終了ということではなく、適切な運用とチューニングが大切です。
起こりうる様々な問題への対応、問題発生を未然に防ぐ方策など、専門的なノウハウを持ったベンダーやシステムインテグレーターの助言を受けることも有効な手段となるでしょう。
Kubernetes の運用を相談したい



Tag: Kubernetes HPA


よく読まれる記事
- 1 Kubernetes のアーキテクチャとは?特徴と基本コンポーネントからデータ保護の方法まで詳しく解説2024.01.30
- 2 Kubernetes マニフェストとは?Kubernetesの構成を定義する方法について解説します!2024.02.01
- 3 Kubernetes DaemonSetとは?概要とその役割、用途、設定や運用上の注意点を解説2024.02.05
- 4 Kubernetesの重要な構成要素である「Node」について解説します!2024.03.25
- 5 Kubernetes Namespace(名前空間)とは?役割や必要性2024.02.06
Category
Contactお問い合わせ
お見積もり・ご相談など、お気軽にお問い合わせください。