




 03-5946-8400
03-5946-8400
 HOME
HOME
目次
はじめに
「障害対応の流れ:事前準備、一次対応、恒久対策の実行」では、障害対応のための事前準備と障害対応の流れを見てきました。ここでは「障害対応を行う際の考え方」について見ていきます。
1. 「階層」を意識してシステムを理解する
システムは、ハードウェアからアプリケーションまで、階層を積み上げて構成されています。よって障害対応を行う際にも、この「階層」を意識すると、障害原因を切り分けやすくなります。
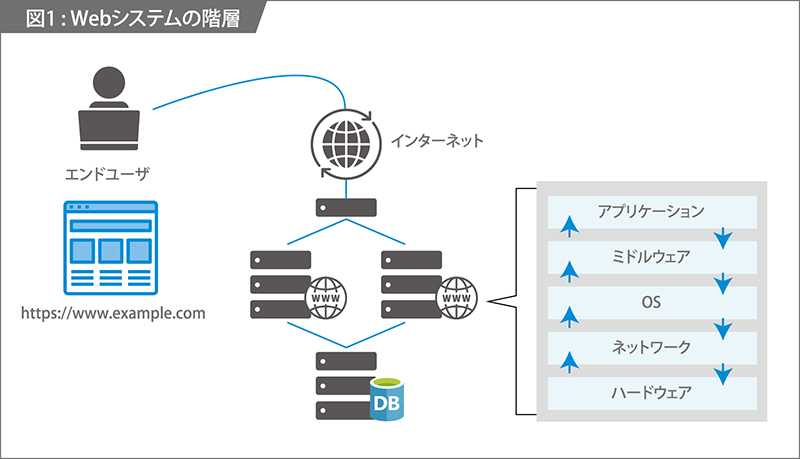
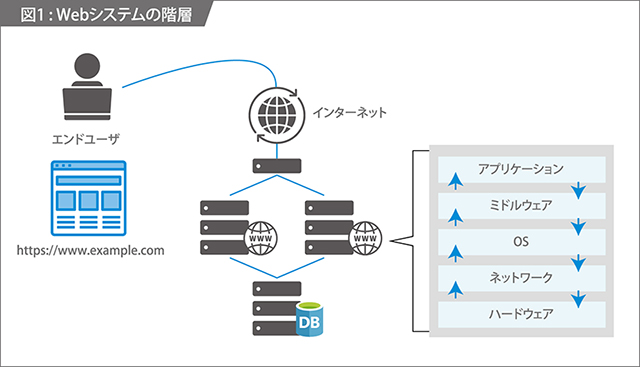
ITシステムは、これらの個々のレイヤ(層)が正常に動作することと同時に、これらが正しく協調することで初めて、機能をユーザに提供することができます。
障害対応時には、システム全体を「階層」で把握した上で
- 階層を上から下へ降りていく
- 下から上へ階層を積み上げていく
という2つの視点を行き来しながら、原因切り分け・対応を行います。
システム運用を行う際には、「そのシステムが正常に稼働し続ける状態」とはどういう状態なのかを、正しく理解することが重要になります。
2. 障害対応時に把握しておくべき情報
先にも述べたように、システムが正常に稼働するには、
- システムを構成する個々のレイヤ(層)が正常に動作すること
- これらが正しく協調すること
が必要です。障害は上記がうまくいっていないために発生するので、各レイヤのポイントを押さえて、原因切り分けをしていきます。
2.1 アプリケーションの情報
・どういう目的で使われるアプリケーションなのか
・具体的にどういう処理を行うのか
・アプリケーションが処理の対象とするデータはどこからインプットされ、どこへアプトプットされるのか
アプリケーション内部の詳細な動きやアルゴリズムについては、開発者でないとわからないことが多く、システム運用の現場ではあまり重視されません。しかし、アプリケーションをブラックボックスとして捉え、上記のような「外部から見た正しい動き」を押さえておくことが、障害対応時に役に立ちます。
2.2 ミドルウェアの情報
・アプリケーションとミドルウェアの動き
・ミドルウェアの構成と配置状況
「アプリケーションとミドルウェアの動き」を把握する
ミドルウェアの代表的なものとしては、次のようなものがあります。
- データベース
- Webサーバー
- Webサーバー、コンテナを含めたWebアプリケーションサーバー
- 開発言語、フレームワーク、ライブラリ
- 特定の機能を提供するためのサーバー、中間ゲートウェイ など
アプリケーションはこのようなミドルウェアを組み合わせ、さらにそれらの API(Application Programming Interface)を用いて開発されます。
また、多くのWebアプリケーションでは、ブラウザをユーザインターフェイスとし、Webサーバーの裏にいるアプリケーションサーバー上のソフトが、さらにその裏に配置されているDBとやり取りすることで、アプリケーションとしての機能を提供します。
このモデルを念頭において「アプリケーションやミドルウェア層の動き」をとらえることも、システムを理解するうえで有効です。
「ミドルウェアの構成と配置状況」を把握する
ミドルウェアの階層は、ネットワーク構成と密接に関係するので、ネットワークをまたいだミドルウェアの動きに注目します。
例えば、DBやアプリケーションサーバーで冗長構成を組む場合、仮想IPアドレスを振ることで、その冗長構成を抽象化することがあります。システムを正確に把握するためには、この抽象化された1つ上の階層から見た構成と、階層を1つ降りた具象化された構成を常に行き来して、その両者の関係性を把握する必要があります。
また、ミドルウェアとノード間を流れるネットワークプロトコルには密接な関係があります。各プロトコルにはプロトコルごとに使用されるポート番号があり、ミドルウェアのプロセスは、それぞれが対応する番号のポートをバインドしています。どのミドルウェアがどのポート番号を使っていて、どこのノードのどのプロセスと通信を行っているか、正確に把握する必要があります。
2.3 OSの情報
・OSの種類、バージョン、OSレベルのコマンド
・RAID構成、HDDのパーティション構成、マウントポイント
OSの種類、バージョン、OSレベルのコマンド
ミドルウェアが動作するためのOSには、次のようなものが使われることが多いです。
- Linux(Red Hat Enterprise Linux, CentOS, SUSE Linux, Debian GNU/Linux, Ubuntu)
- Windows
- FreeBSD
- Solaris
- HP-UX
システムが安定動作するためのメンテナンス作業や、稼働状況のモニタリングを行う際には、OSレベルのコマンドを直接、頻繁に使うことになります。
コマンドレベルでは、コマンド有無そのものからコマンド名、あるいぱパラメータの指定方法、コマンド実行結果の表示フォーマットに至るまで、OS間の差異があるので注意が必要です。
RAID構成、ディスクのパーティション構成、マウントポイント
OSはクラウド基盤や物理サーバのハードウェア上で稼働します。OSの種類、バージョン、RAID構成(物理サーバの場合)、ディスクパーティション構成、各パーティションのマウントポイント(各パーティションにアクセスするためのディレクトリ)も、システム構成を把握するためには重要な情報です。
この階層では、システムがログを吐き続けるので、ディスク領域の空き容量なども注意しましょう。
2.4 ネットワークの情報
・システム全体を構成する各ノードの役割
・ネットワークのIPアドレス、ルーティング経路、トポロジー構成など
システム全体を構成する各ノードの役割を把握する
たいていのシステムでは、複数のノードに役割を分担させ、全体として1つの大きなシステムを構成しています。例えば、複数のWebサーバーを並列に配置し、ロードバランサーなどで負荷分散を行ったり、複数配置されたDBサーバー間でレプリケーション(複製)を設定し、不測の事態に備えるような構成にすることも多いです。
このようにハードウェア(ノード)やOSの階層で把握できるシステム構成からさらに抽象化し、各ノードを一構成要素として、システム全体を把握することで、システムのアーキテクチャをより正確に理解できるようになります。
ネットワークのIPアドレス、ルーティング経路、トポロジー構成などを把握する
この階層では、ネットワークのIPアドレスや、ルーティング経路、ネットワークのトポロジー構成も必要になります。ノード間に流れるネットワークプロトコルの種類やその経路、各プロトコルがどこで終端されるのかといった情報や、ファイアウォールによるパケットフィルタリングの設定情報なども、ネットワークに起因するトラブルを解決する上で重要な情報です。
2.5 ハードウェアの情報
機器の構成情報:
・ハードウェアベンダ、機種名
・CPUの数
・メモリ搭載量
・HDDの数と搭載量
・RAIDコントローラの有無
・ネットワークインターフェイスの数
物理サーバの場合、HDDなどは、RAIDを構築することが多く、たいていは複数搭載されています。その場合、OSなどから見えるデバイスIDが、実際のどのHDDに対応するのかを確認しておきます。
特に、ハードウェアを外部のデータセンターに置いている場合は、普段はリモートで操作することが多くなります。機種の型番は、リモートからでは把握しづらい情報なので、予め確認しておきます。
以上のように、障害対応時には、システムを構成する「階層」を行き来しながら、原因を切り分けをしていくことになります。次は、「障害対応事例:「階層」を行き来して原因を切り分ける」で、階層を上下に行き来しながら障害対応をする例を見ていきます。
関連サービス

24時間365日のシステム監視・障害対応を任せたい
障害発生時には、エンジニアが手順に基づく対応に加えて、技術的ノウハウに基づく対応を行い、サービスを復旧させます。また、障害の根本解決方法をご提案します。

大規模システム向け統合システム監視ツール Pandora FMS Enterprise
世界194か国から120万ダウンロード以上の支持を得るオープンソースの監視ツール Pandora FMSに、大規模システム向け機能を追加した Pandora FMS Enterprise。オープンソースベースの商用製品だから実現できる「運用コストの削減」と「使い勝手の良さ」が特徴です。


資料ダウンロード
課題解決に役立つ詳しいサービス資料はこちら

-
-
システム運用代行サービスカタログ
システム運用代行サービスのメニューと料金をご確認いただけます。
-
-
-
運用設計が丸わかり!クラウド運用課題解決への4ステップ(運用設計ガイド)
クラウド運用課題を解決する「運用設計の考え方」「運用設計のフレームワーク」のポイントを解説します。
-
-
-
統合システム監視ツール Pandora FMS Enterprise カタログ
直感的で操作性に優れたユーザインターフェイスを持ち、1つのシステムでマルチテナント環境を実現できる統合システム監視ツール Pandora FMS Enterprise、Pandora FMS Enterprise SaaS の機能、サポート内容、料金をご確認いただけます。
-




Contactお問い合わせ
お見積もり・ご相談など、お気軽にお問い合わせください。