




 03-5946-8400
03-5946-8400
 HOME
HOME
目次
Azure Data Lakeのユースケースも紹介
DX (デジタル・トランスフォーメーション)を見据えてクラウドを利用する企業が増えています。企業が DX を推進する上でなくてはならない仕組みに、データ分析があります。データ分析を行う上で、データベースやデータウェアハウスなど、データを保存・管理する技術は多いですが、その中でも雑多な非構造化データを扱うデータレイクは特に重要な役割を担っています。
クラウド上でデータレイクを実現するために、 Azure では、Azure Data Lake というサービスが用意されています。本記事では、企業の DX に必要なデータレイクの仕組みを踏まえ、 Azure Data Lake の概要や構成、特徴とメリットについて解説します。
1. データレイクとは
DX を推進する企業が増えるにつれて、データレイクという言葉をよく耳にするようになりました。まず、データレイクの概要と目的、必要性、そして混同されやすいデータウェアハウスやデータマートとの違いについて解説します。
データレイクとは
データレイクとは、膨大なビッグデータをそのまま(生データのまま)格納・蓄積できるストレージのことを指します。規則性を持った構造化データ、非構造化データを問わず、どのようなデータでも格納することができます。
特に、音声や動画、 SNS のログ、センサーデータなどを含むあらゆる形式の非構造化データを、そのままの形式で貯めておけることが大きな特徴であり利点でもあります。
データレイクの目的と用途
データレイクはビッグデータの処理を目的として開発されています。構造化・非構造化を問わずどのようなデータでも格納できるため、センサーデータや GPS データ、 SNS のテキストなど、ビジネスを行う中で産み出される生データをそのままの形で保存・管理できます。
テーブル構造に縛られるリレーショナルデータベース( RDBMS )では、このような非構造化データをそのまま取り扱うことが苦手ですが、データレイクなら、雑多な非構造化データを加工・変換することなく、そのままの形で扱うことが可能です。
データレイクの必要性
データレイクが必要とされているのは、データマイニングの原資となるからです。そもそもデータマイニングは、膨大なデータからビジネスに役立つ知見を見つけ出すことを指します。データマイニングを実施するためには、あらゆるデータをそのまま蓄積できるデータレイクが欠かせません。
データレイクには多様なデータが保存されており、分析担当者が気づかない価値のあるデータが眠っている可能性があります。たとえば、 SNS の口コミデータを分析することで、新たな市場の動向や顧客のニーズを発見できるかもしれません。
データウェアハウス( DWH )との違い
データレイクは、よくデータウェアハウスと混同されます。データウェアハウス( DWH )とは、企業の意思決定を支援するための大規模なビジネスデータを保管した「データの保管庫」で、データレイクと同様に大量のデータを蓄積する仕組みです。
しかし、データウェアハウスは、非構造化データの扱いを得意とするデータレイクと違い、規則性を持った構造化データを収集し、目的別に定義された形に格納します。データウェアハウスで扱うデータは、データ分析業務で利用するために最適化されたデータ構造となっている必要があります。
データマートの違い
データレイクとデータマートは、どちらも企業のデータ管理・分析に活用されていますが、データの格納方法や活用目的が大きく異なります。
データマートとは、特定の業務や部門での分析を目的とした、必要なデータだけを抽出・加工して最適化したデータベースのことです。データが整理・加工されているため、迅速なレポート作成や分析が可能になります。データレイクは分析の可能性を広げますが、データが整理されていないため、活用する際は適切な処理が不可欠です。一方、データマートはすぐに使えるデータを提供できますが、保存されるデータは限定的になります。
データレイクとデータマートは、企業のデータ活用戦略に応じて、適切に使い分けることが重要です。
2. データレイクのメリット
データレイクのメリットは下記の 4 つです。
- 低コストで大容量のデータを保存できる
- データのサイロ化を防止できる
- セキュリティとデータガバナンスを強化できる
- クラウドサービスとシームレスに連携できる
低コストで大容量のデータを保存できる
データレイクは、ログや画像、動画、 SNS データなどの非構造化データも格納できます。通常のデータベースよりもコスト効率よく、大容量のデータを管理できるのがメリットです。特にクラウドベースのデータレイクを利用すれば、必要な分だけリソースを確保できるため、無駄なコストを抑えられます。
データのサイロ化を防止できる
データのサイロ化とは、部門やシステムごとにデータが分断され、全社的なデータ活用が困難になる状態のことです。多くの企業では、部署ごとに異なるデータベースやツールを利用しているため、データの一元管理が難しく、部門間でのデータ共有や統合が妨げられるという課題があります。
データレイクを導入することで、企業内のすべてのデータを一箇所に集約し、横断的に活用できる環境を整えることが可能です。マーケティングや営業、財務、製造部門など、異なる部門間でのデータの共有がスムーズになり、全社的なデータ活用を実現できます。
セキュリティとデータガバナンスを強化できる
データレイクは、企業のデータ管理を強化し、セキュリティやガバナンス(データの適切な管理と利用)を向上させることが可能です。データレイクを導入することで、データへのアクセス権限を細かく設定し、不正アクセスや情報漏えいのリスクを低減できます。
たとえば、機密情報は特定のユーザーのみに閲覧権限を付与し、一般データは社内の複数部署が参照できるように設定します。これにより、データの適切な利用を促進しながらセキュリティを確保することが可能です。
また、データレイクはデータのライフサイクル管理にも適しています。一定期間経過したデータをアーカイブしたり、データの品質管理を一元的に実施したりすることも可能です。データの整合性を保ちながら、コンプライアンス要件にも対応しやすくなるでしょう。
クラウドサービスとシームレスに連携できる
データレイクは、クラウド環境との親和性が高く、さまざまなクラウドサービスと連携できるのも大きなメリットです。たとえば、複数のデータソースからの情報をリアルタイムで取り込み、機械学習やデータ分析に活用できます。
また、クラウドプロバイダーが提供するストレージやコンピューティング、データ処理機能と統合しやすいため、データの保存・処理・活用を一元的に管理することも可能です。
3. データレイクはオンプレミスとクラウドのどちらで構築すべき?
データレイクの構築方法は、大きくオンプレミスとクラウドの 2 つに分けられます。ここでは、それぞれの方法のメリット・デメリットを解説します。
オンプレミスで構築するメリット・デメリット
オンプレミスでデータレイクを構築する(自社のデータセンターやサーバー上にデータレイク環境を構築・運用する)場合、すべてのデータを社内のネットワーク内に保持できます。
オンプレミスで構築するメリットは、機密情報の管理やコンプライアンスの要件を満たしやすい点です。自社でセキュリティポリシーを設定でき、データの暗号化やアクセス制御を細かく管理できます。
ただし、サーバーやストレージ、ネットワーク機器の購入や設置に大きなコストがかかるのがデメリットです。電力・冷却設備の維持やハードウェアのメンテナンスなどでもコストが発生します。
クラウドで構築するメリット・デメリット
クラウドでデータレイクを構築する場合、必要に応じてストレージやコンピューティングリソースを即座に増減できるため、データの急激な増加にも対応しやすいのがメリットです。ビジネスの成長に応じて、無駄なコストを抑えながら最適なリソースを確保できます。サーバーやストレージの購入が不要なため、初期投資を抑えられるのもメリットです。
デメリットは大量のデータをクラウドにアップロード・ダウンロードする際にコストが発生する可能性がある点です。また、クラウドプロバイダーの料金体系やサービス仕様の変更に影響を受けることもあります。
オンプレミスで構築する方法がおすすめなのは、主に機密情報を社内で厳格に管理したい企業です。一方でデータの増減に応じて必要なときにリソースを拡張し、不要なときはコストを抑えたい企業にとっては、クラウドで構築するのがおすすめです。
4. Azure Data Lake とは
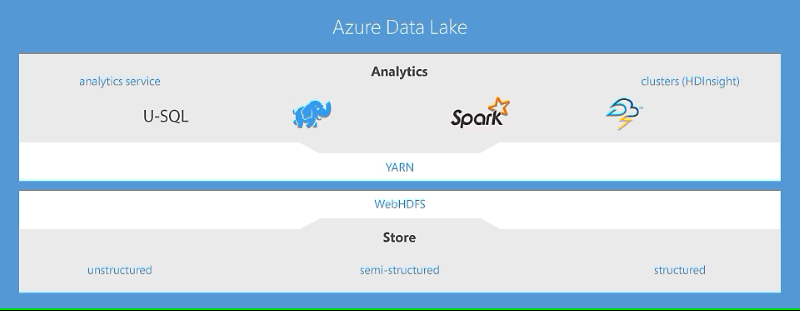
図版出典:Microsoft公式サイト
マイクロソフトが提供するクラウド、 Microsoft Azure では、クラウドの利点を最大限に活用したデータレイクサービスを提供しています。ここでは、 Azure Data Lake の概要と料金体系について解説します。
Azure Data Lake の概要
Azure Data Lake は、 Azure が提供するデータレイクを実現するサービスです。データ格納領域の「 Azure Data Lake Storage 」と分析ツール「 Azure Data Lake Analytics 」、管理機能「 Azure HDInsight 」から構成されます。データレイクとしてさまざまな種類のデータを簡単に取り扱うことができ、 Azure の持つ高い可用性とスケーラビリティを活かし、ペタバイト規模のファイルと数十億個のオブジェクトを保存して分析することが可能です。
Azure Data Lake の料金体系
Azure Data Lake の料金体系は、利用した分だけ支払う従量課金制です。下記の通り、 Azure Data Lake を構成する 3 つのサービス単位で料金が必要となります。
Azure Data Lake Storage
データ容量に応じた月額従量課金
Azure Data Lake Analytics
分析ジョブ実行時間に応じた従量課金制
Azure Data Lake Analytics の料金算出はこちらから
Azure HDInsight
コンポーネントとインスタンスサイズの組み合わせによる、実行時間に応じた従量課金制
5. Azure Data Lake の構成とメリット
Azure Data Lake は 3 つのサービスで構成されているとお伝えしましたが、それぞれのサービスにはどのような特徴やメリットがあるのでしょうか。 Azure Data Lake を構成するサービスの概要と、 Azure Data Lake のメリットについて解説します。
Azure Data Lakeの構成
Azure Data Lake は下記のサービスで構成されています。
Azure Data Lake Storage
Azure Data Lake Storage は、データレイクを構築するためのストレージサービスです。ビッグデータ分析用のスケーラブルで費用対効果の高いストレージサービスであり、 Azure Blob Storage と既存の Azure Data Lake Storage Gen1 の機能を集約したものです。ペタバイト単位の膨大なエンタープライズ向けのビッグデータを蓄積・管理できます。
Data Lake Analytics
Data Lake Analytics は、オープンソースのエンタープライズ向け分析サービスです。ペタバイト規模のデータに対して、超並列のデータ変換および処理プログラムを、 U-SQL 、 R 、 Python 、 .NET で容易に開発および実行できます。
Azure HDInsight
Azure HDInsight は、 Azure クラウド上で動作する分散データ処理基盤です。フルマネージドの Apache Spark および Hadoop 上で、ビッグデータを分析に適した形式にするための分散処理を行えます。 99.9% の SLA が保証されており、 Spark 、 Hive 、 MapReduce 、 HBase 、 Storm 、 Kafka 、 R Server 向けに最適化されています。
Azure Data Lakeの特徴とメリット
Azure Data Lake の特徴とメリットは下記の通りです。
ビッグデータプログラムの開発の簡略化
ビッグデータを操作するクエリを設計し実装することはテクニカルで難しい場合があります。 Azure Data Lake では、 Visual Studio 、 Eclipse 、 IntelliJ などさまざまな開発ツールと統合されているため、使い慣れているツールを使って簡単にコードを実行、デバッグ、調整することが可能です。
既存システムとのシームレスな統合
ビッグデータ活用の大きな課題の 1 つは、既存 IT 資産とどのように融合させるかという点です。 Azure Data Lake は、 Azure Synapse Analytics 、 Power BI 、 Data Factory と連携して、 Azure クラウド上で、高度な分析に対応した包括的なプラットフォームを実現することが可能です。
また、仮想マシン上の Azure SQL Server 、 Azure SQL Database 、 Azure Synapse Analytics などのデータベースサービスと対応しており、すべてのデータに対応できます。
無限のスケールによりペタバイト規模のデータ保存が可能
Azure Data Lake のアーキテクチャは、クラウドの高い性能とスケーラビリティを享受するために最適化されています。 Azure Data Lake Store では、スケーラビリティの制限を受けずに組織のデータすべてを単一の場所で分析することが可能です。 Data Lake Store では数十億個のファイルを保存でき、サイズ上限は他のクラウドストアの 200 倍以上となっています。 1 ペタバイトを超えるファイルも保存可能です。
エンタープライズグレードのセキュリティ
Azure Data Lake は、マイクロソフトにより完全に管理とサポートがされており、エンタープライズグレードの SLA と 24 時間 365 日対応のサポートが付属しています。データは、転送中は SSL を使用して、保存時には Azure Key Vault で HSM(暗号鍵管理システム)に保管された暗号鍵により、常に暗号化されます。
また、 Microsoft Entra ID を通じて、シングル サインオン(SSO)や多要素認証などの機能も組み込むことが可能です。
6. Azure Data Lakeのユースケース
Azure Data Lake は下記の用途で活用できます。
- IoTデータの収集・分析
- 大規模なログデータの保存・分析
- ビッグデータを活用したマーケティング分析
それぞれの内容を解説します。
IoTデータの収集・分析
Azure Data Lake は、 IoT ( Internet of Things )デバイスから送られてくる大量のデータをリアルタイムで収集・保存し、分析するための基盤として活用できます。たとえば、製造業の予知保全やスマートシティの交通管理、小売業のスマート店舗などで活用することが可能です。
大規模なログデータの保存・分析
Azure Data Lake は、企業のシステムやアプリケーションから生成される大量のログデータを一元管理し、セキュリティ監視やトラブルシューティング、業務最適化などでも活用できます。膨大なログデータをリアルタイムで処理し、高速に検索・分析することが可能です。
たとえば、銀行や証券会社の取引ログを蓄積し、不正取引のパターンを学習することができます。異常な振込やアクセスを検出し、自動でアラートを発生させることも可能です。
ビッグデータを活用したマーケティング分析
Azure Data Lake を活用すれば、複数のデータソースを統合し、リアルタイムで大規模なデータを分析することも可能です。マーケティング施策の最適化や売上向上などを実現できます。たとえば、新商品の発売前に SNS 上の反応を分析し、広告キャンペーンの効果を予測することが可能です。
7. まとめ
データレイクは企業の DX を支える技術です。企業がビジネスを遂行する中で産み出される大量のデータを一箇所にまとめ、多角的に分析を行うことで新しいサービスを産み出せる可能性が高まります。
Azure Data Lake は、 Azure の高い可用性、スケーラビリティ、セキュリティを備えたデータレイクサービスです。新しいビジネスを産み出すために導入を検討してみてはいかがでしょうか。Azure の導入を相談したい


資料ダウンロード
課題解決に役立つ詳しいサービス資料はこちら

-
-
Azure導入支援・構築・運用サービス総合カタログ
Microsoft Azure サービスの導入検討・PoC、設計、構築、運用までを一貫してご支援いたします。
Azure導入・運用時のよくあるお悩み、お悩みを解決するためのアールワークスのご支援内容・方法、ご支援例などをご確認いただけます。
-
Microsoft Azureを利用したシステムの設計・構築を代行します。お客様のご要件を実現する構成をご提案・実装いたします。

Tag: Azure Data Lake ビッグデータ


よく読まれる記事
- 1 Visual Studio Code とは?Visual Studioとの違い・メリット・使用方法を解説2023.05.23
- 2 Microsoft Entra IDとは?Azure ADとの違い・導入メリット・主な機能を解説2024.04.05
- 3 Azure Bastionとは?踏み台サーバーの仕組み・機能・メリットを詳しく解説2022.05.12
- 4 Microsoft Defender for Cloudとは?機能や料金、有効化する方法を解説2025.02.26
- 5 Azure AI Foundryとは?その機能や活用方法を解説2025.07.26
Category



Contactお問い合わせ
お見積もり・ご相談など、お気軽にお問い合わせください。