




 03-5946-8400
03-5946-8400
 HOME
HOMEシステムのクラウド移行が加速する中、「クラウドサービスを活用しているが、クラウド毎に個別に監視・運用をしているため、運用が煩雑化している。どうすればよいか?」「オンプレミスとクラウドを併用することになり、運用管理体制を見直したい」といったお声をいただくことも多くなりました。
システムは構築して終わりではなく、安定稼働するための運用が重要です。そして、システム運用の品質を担保しながら効率を上げていくためには、運用設計が必要となります。
この連載では、運用設計の考え方やの取り組みについて、事例も交えて紹介します(全12回)。
はじめに
今回は、「ITサービスの可用性管理」をテーマにお話しします。
可用性管理とは
目的
可用性とは、情報を使いたいときに使える状態にしておくことです。可用性管理の目的は、合意済みのサービスレベル目標値を満たすように、ITサービスの可用性を最適化、改善していくことになります。
一般的には、SLAで合意されたレベルの維持を目標とし、その目標を達成するために4つの要素(可用性、信頼性、保守性、サービス性)の監視、測定、分析、改善を行います。
(関連コラム:「第11回:可用性を高めるための監視仕様」、「第12回:可用性を高めるための障害対応手順」)
可用性管理を行うことで、現在や将来のITサービスに対する可用性のニーズに、適切なタイミングで対応できるようになります。
行うこと
可用性管理では、ITシステムの稼働が停止することのないよう、設計・実装・報告・改善までの一連のプロセスを行います。
ITILでは下記のように記載されています。
1.設計
バックアップと復旧方法
想定されるリスク・障害発生ポイントを洗い出し、バックアップ手法、復旧手法を策定します。
想定内リスクとして、「データ破壊」「ハードウェア故障」「ネットワーク障害」「電源の一時的な供給停止」などが挙げられます。リスクを回避するための計画的な回避措置として、「定期的なデータバックアップ」「待機系の準備と切り替え手順の作成」「ネットワークの二重化」「電源の二重化やUPS設置」などがあります。
また、リスクが発生した場合の復旧手順もあらかじめ作成しておく必要があります。「DB障害時の、バックアップデータからの復旧手順の作成」「待機系への切り替え後の、正常系への復旧手順の作成」などがあります。
可用性を高める設計
可用性とは、ユーザーがITサービスを利用できる能力を指します。可用性は以下の式で計算できます。

可用性の測定は、障害発生の全体的な傾向をつかむために有効です。また、耐障害性を上げる施策を行うためには、合意済みのサービス時間だけでなく、総ダウンタイム時間の測定も有効です。
可用性を向上させるためには、コンポーネント(サーバーなど)や構成アイテム(ディスクなど)を冗長化するとともに、サービスの正常性を常時監視し、障害発生時には迅速に対応できるような体制を構築することが有効です。
信頼性を高める設計
信頼性とは、サービス、コンポーネント(サーバーなど)、構成アイテム(ディスクなど)がどの程度故障しにくいのかを示す指標です。一般的に、平均故障間隔(MTBF: Mean Time Between Failures)で測定されます。下記の計算式で算出され、構成アイテムまたはITサービスが、合意済みの機能を中断なく実行できる時間の平均値を表します。
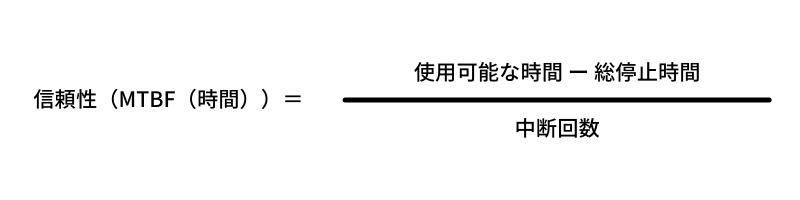
信頼性はコンポーネントを冗長化し負荷分散することで、信頼性を向上させることができます。またMTBF を継続監視する仕組みや体制を作ることで、信頼性の改善につなげることができます。
保守性を高める設計
保守性は、障害が発生し、サービスが停止してから回復する能力を言います。ダウン状態から早く回復できるほど、保守性が高くなります。通常、保守性は、平均サービス回復時間(MTRS: Mean Time to Restore Service)で計測され、障害発生後、構成アイテムやITサービスを回復させるためにかかる時間の平均値を表します。可用性や信頼性を高めることで、保守性も高めることができます。
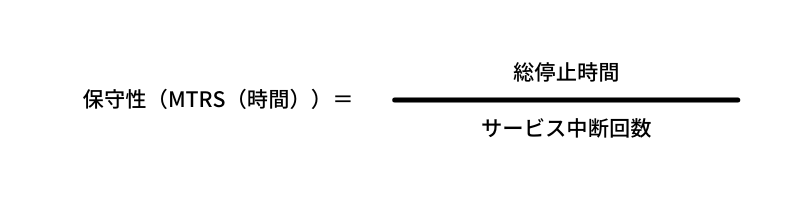
サービス性を高める設計
サービス性とは、サードパーティ・サプライヤが持つ契約条件を満たす能力のことをいいます。サプライヤーとの契約時に合意した、可用性、信頼性(MTBF)、保守性(MTRS)を測定し、定期的に評価する体制を用意することが有効です。
2.実装
設計フェーズで策定した内容を、システム構築や運用体制構築に反映します。
3.監視・報告
可用性、信頼性、保守性を計測するための指標を監視し、あらかじめ定めた閾値を超えた場合は、事前に定めた手順で対応するとともに、関係者へ報告します。
4.改善
監視結果を定期的にレビューし、改善策を実行します。
可用性管理の取り組み事例
可用性管理の取り組み事例として、当社の例を取り上げてご紹介していきます。自社で取り組む際の参考になれば幸いです。
当社は、24時間365日のシステム運用サービスとクラウド構築サービス、クラウド型監視サービスをご提供しており、サービスの稼働が停止することのないよう以下の3要素で管理しています。
可用性
可用性は、SLAで合意した稼働時間に対しどの程度稼働するかを示すものです。お客様と合意した計画メンテナンス時間を除外したうえで、システムを構成する機器の冗長化、データセンタ電源の冗長化、インターネット回線の冗長化、データの保全により100%の稼働率を保っています。
稼働率は、24時間365日の稼働監視結果からサービス提供が行えた時間を月の総時間で除算した結果で算出しています。
24時間365日の監視を維持するための体制作りや、仮に欠員が生じた場合などのシフト変更や補充体制、事故・災害等により出社出来なかった場合などのリモートサイト環境を整えています。また、チケットシステムやグループチャットを利用した情報の共有・伝達を行うなど、サービスが中断・停止することのない仕組みも整えています。
信頼性
信頼性とは、システムが中断せずに利用できるかを示す指標であり、一般的にはMTBF(平均故障間隔)として表現されます。平均故障間隔とは、停止状態から回復し、次に停止するまでの平均時間を意味します。
当社では、システムを構成する機器の冗長化、データセンタ電源の冗長化、インターネット回線の冗長化、データの保全により停止のリスクを限りなくゼロに抑えると共に、システムで使用している部位については冗長化機構を取り入れ、仮に片系の部位に故障が発生したとしてもホットスワップにより無停止で交換が行える機材を導入し信頼性を向上させています。
保守性
保守性とは、停止状態からシステムが稼働開始する能力を示す指標であり、一般的にMTRS(平均サービス回復時間)として表現されます。平均サービス回復時間は、一度の停止から回復までの所要時間を示しています。
当社システムは、複数のシステムが結合して一つのサービスを形成していることから、個々のシステムの可用性や信頼性を高めることを重視し、保守性は可用性、信頼性の一部として管理しています
まとめ
今回は、運用体制構築するための前提である「何を、どう管理するのか」の1つ、「可用性管理プロセス」に ついて、取り組み事例(当社の場合)も交えてご紹介しました。
ITサービスの提供レベルを、「可用性」「信頼性」「保守性」の観点から定常的に監視、分析、改善することで、現在や将来のITサービスに対する可用性のニーズに、適切なタイミングで対応できるようになるでしょう。ぜひ自社の取り組みに取り入れてみてください。
次回は、「ITサービス継続性管理」についてお話しします。
運用設計のポイントを手っ取り早く把握したい方へ
クラウド運用課題を解決する「運用設計の考え方」「運用設計のフレームワーク」のポイントを手っ取り早く把握したい!という方は、以下のホワイトペーパー「運用設計が丸わかり!クラウド運用課題解決への4ステップ(運用設計ガイド)」もあわせてご参照ください。
「クラウド運用の課題と対応策」や「自社で運用設計する際の課題」、「運用設計と継続的な運用改善を継続させるポイント」も記載していますので、参考になさってください。



Tag: 運用設計


関連記事
-

第1回:運用設計を行うべき理由と運用設計のアプローチ2021.02.08
-
第2回:運用設計の考え方―何を管理するのか?運用管理対象の洗い出し方2021.02.08
-
第3回:運用設計の考え方―運用管理対象をどういう視点で管理するのか?運用要件から落とし込むときのポイント2021.02.08
-
第4回:システム運用方針のまとめ方と、運用体制構築に必要なこと2021.02.09
-
第5回:サービスレベル管理とは?―運用体制構築に向けての考え方と取り組み事例(1)2021.02.09
-
第6回:可用性管理とは?―運用体制構築に向けての考え方と取り組み事例(2)2021.02.09
-
第7回:ITサービス継続性管理とは?―運用体制構築に向けての考え方と取り組み事例(3)2021.02.09
-
第8回:キャパシティ管理とは?―運用体制構築に向けての考え方と取り組み事例(4)2021.02.09
-
第9回:情報セキュリティ管理とは?―運用体制構築に向けての考え方と取り組み事例(5)2021.02.09
-
第10回:構成管理とは―目的と取り組み事例2021.02.09
-
第11回:可用性を高めるための監視仕様2021.02.09
-
第12回:可用性を高めるための障害対応手順2021.02.09
-
運用設計とは?サービスを安定稼働させるための項目定義2019.01.24



Contactお問い合わせ
お見積もり・ご相談など、お気軽にお問い合わせください。